Examples of Merge Statement’s Output Clause
We are using the same tables and merge statement as used in an
example previously. Below are just four simple ways you can use output clause with the merge statement.
Example 1 of Output clause: In this first example, @MergeOutput1 is declared as a table variable. It has columns for old mobile names and new mobile names. Similarly columns for old company names and new company names are there. ActionType column shows the type of modification that is performed on the table when rows are merged. Lastly it also has a MobileID column which is common to both the tables Mobiles and Mobiles_New.
Output clause of the merge statement is inserting the values in the @MergeOutput1 variable. At last we are using select statement to view the rows of the @MergeOutput1 table variable.
CREATE TABLE [Mobiles]
(
[MobileID] [int] PRIMARY KEY,
[MobileName] [nvarchar](64),
[Company] [nvarchar](50)
);
CREATE TABLE [Mobiles_New]
(
[MobileID] [int] PRIMARY KEY,
[MobileName] [nvarchar](64),
[Company] [nvarchar](50)
);
INSERT INTO [Mobiles]
VALUES ( 1, 'Nokia 100', 'MS' )
, ( 2, 'Nokia 120', 'MS' )
, ( 3, 'Nokia 130', 'MS' )
, ( 4, 'N72', 'Nokia' )
, ( 5, 'P21', 'Panaonic' )
, ( 6, 'M69', 'Micromax' );
INSERT INTO [Mobiles_New]
VALUES ( 1, 'Microsoft 100', 'Microsoft' )
, ( 2, 'Microsoft 120', 'Microsoft' )
, ( 3, 'Microsoft 130', 'Microsoft' )
, ( 4, 'Nokia 72', 'Microsoft' )
, ( 7, 'iPhone', 'Apple' );
Select * from Mobiles
Select * from Mobiles_New
DECLARE @MergeOutput1 table
(
ActionType nvarchar(10),
MobileID int,
OldMobileName nvarchar(65),
NewMobileName nvarchar(65),
OldCompany nvarchar(55),
NewCompany nvarchar(55)
);
MERGE [dbo].[Mobiles] AS [OLD_Tbl]
USING [dbo].[Mobiles_New] AS [New_Tbl]
ON ( OLD_Tbl.[MobileID] = New_Tbl.[MobileID] )
WHEN MATCHED AND OLD_Tbl.[MobileName] <>
New_Tbl.[MobileName]
OR OLD_Tbl.[Company] <> New_Tbl.[Company] THEN
UPDATE SET OLD_Tbl.[MobileName] = New_Tbl.[MobileName]
,
OLD_Tbl.[Company] = New_Tbl.[Company]
WHEN NOT MATCHED THEN
INSERT ( [MobileID] ,
[MobileName] ,
[Company]
)
VALUES ( New_Tbl.[MobileID] ,
New_Tbl.[MobileName] ,
New_Tbl.[Company]
)
WHEN NOT MATCHED BY SOURCE THEN
DELETE
OUTPUT
$Action ,
INSERTED.MobileID,
DELETED.MobileName,
Inserted.MobileName,
DELETED.Company,
Inserted.Company
INTO @MergeOutput1;
Select * from @MergeOutput1;
Result:
 Example 2 of Output clause:
Example 2 of Output clause: INSERTED is a column prefix that specifies the value added by the insert or update operation. In simple words when using output clause, a table called the inserted table is created for all the insert operations. A table called the deleted table is created for delete operations.
Here we are showing all three columns i.e. MobileID, MobileName and Company using "INSERTED" column prefix with "*".
Drop table Mobiles
Drop table Mobiles_New
CREATE TABLE [Mobiles]
(
[MobileID] [int] PRIMARY KEY,
[MobileName] [nvarchar](64),
[Company] [nvarchar](50)
);
CREATE TABLE [Mobiles_New]
(
[MobileID] [int] PRIMARY KEY,
[MobileName] [nvarchar](64),
[Company] [nvarchar](50)
);
INSERT INTO [Mobiles]
VALUES ( 1, 'Nokia 100', 'MS' )
, ( 2, 'Nokia 120', 'MS' )
, ( 3, 'Nokia 130', 'MS' )
, ( 4, 'N72', 'Nokia' )
, ( 5, 'P21', 'Panaonic' )
, ( 6, 'M69', 'Micromax' );
INSERT INTO [Mobiles_New]
VALUES ( 1, 'Microsoft 100', 'Microsoft' )
, ( 2, 'Microsoft 120', 'Microsoft' )
, ( 3, 'Microsoft 130', 'Microsoft' )
, ( 4, 'Nokia 72', 'Microsoft' )
, ( 7, 'iPhone', 'Apple' );
Select * from Mobiles
Select * from Mobiles_New
MERGE [dbo].[Mobiles] AS [OLD_Tbl]
USING [dbo].[Mobiles_New] AS [New_Tbl]
ON ( OLD_Tbl.[MobileID] = New_Tbl.[MobileID] )
WHEN MATCHED AND OLD_Tbl.[MobileName] <>
New_Tbl.[MobileName]
OR OLD_Tbl.[Company] <> New_Tbl.[Company] THEN
UPDATE SET OLD_Tbl.[MobileName] = New_Tbl.[MobileName]
,
OLD_Tbl.[Company] = New_Tbl.[Company]
WHEN NOT MATCHED THEN
INSERT ( [MobileID] ,
[MobileName] ,
[Company]
)
VALUES ( New_Tbl.[MobileID] ,
New_Tbl.[MobileName] ,
New_Tbl.[Company]
)
WHEN NOT MATCHED BY SOURCE THEN
DELETE
OUTPUT
$Action,
INSERTED.*;
Result:
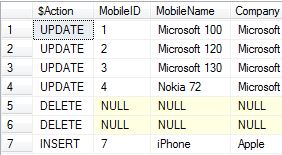 Example 3 of Output clause:
Example 3 of Output clause: Here, in this example, instead of using "*" to show all the columns we have used "." to show individual columns which we want to see in the result.
Drop table Mobiles
Drop table Mobiles_New
CREATE TABLE [Mobiles]
(
[MobileID] [int] PRIMARY KEY,
[MobileName] [nvarchar](64),
[Company] [nvarchar](50)
);
CREATE TABLE [Mobiles_New]
(
[MobileID] [int] PRIMARY KEY,
[MobileName] [nvarchar](64),
[Company] [nvarchar](50)
);
INSERT INTO [Mobiles]
VALUES ( 1, 'Nokia 100', 'MS' )
, ( 2, 'Nokia 120', 'MS' )
, ( 3, 'Nokia 130', 'MS' )
, ( 4, 'N72', 'Nokia' )
, ( 5, 'P21', 'Panaonic' )
, ( 6, 'M69', 'Micromax' );
INSERT INTO [Mobiles_New]
VALUES ( 1, 'Microsoft 100', 'Microsoft' )
, ( 2, 'Microsoft 120', 'Microsoft' )
, ( 3, 'Microsoft 130', 'Microsoft' )
, ( 4, 'Nokia 72', 'Microsoft' )
, ( 7, 'iPhone', 'Apple' );
Select * from Mobiles
Select * from Mobiles_New
MERGE [dbo].[Mobiles] AS [OLD_Tbl]
USING [dbo].[Mobiles_New] AS [New_Tbl]
ON ( OLD_Tbl.[MobileID] = New_Tbl.[MobileID] )
WHEN MATCHED AND OLD_Tbl.[MobileName] <>
New_Tbl.[MobileName]
OR OLD_Tbl.[Company] <> New_Tbl.[Company] THEN
UPDATE SET OLD_Tbl.[MobileName] = New_Tbl.[MobileName]
,
OLD_Tbl.[Company] = New_Tbl.[Company]
WHEN NOT MATCHED THEN
INSERT ( [MobileID] ,
[MobileName] ,
[Company]
)
VALUES ( New_Tbl.[MobileID] ,
New_Tbl.[MobileName] ,
New_Tbl.[Company]
)
WHEN NOT MATCHED BY SOURCE THEN
DELETE
OUTPUT
$Action,
INSERTED.MobileID,
INSERTED.MobileName,
INSERTED.Company;
Result:
 Example 4 of Output clause:
Example 4 of Output clause: You can refer any column of the source table (Mobiles_New in our case) in the merge statement's output clause.
Drop table Mobiles
Drop table Mobiles_New
CREATE TABLE [Mobiles]
(
[MobileID] [int] PRIMARY KEY,
[MobileName] [nvarchar](64),
[Company] [nvarchar](50)
);
CREATE TABLE [Mobiles_New]
(
[MobileID] [int] PRIMARY KEY,
[MobileName] [nvarchar](64),
[Company] [nvarchar](50)
);
INSERT INTO [Mobiles]
VALUES ( 1, 'Nokia 100', 'MS' )
, ( 2, 'Nokia 120', 'MS' )
, ( 3, 'Nokia 130', 'MS' )
, ( 4, 'N72', 'Nokia' )
, ( 5, 'P21', 'Panaonic' )
, ( 6, 'M69', 'Micromax' );
INSERT INTO [Mobiles_New]
VALUES ( 1, 'Microsoft 100', 'Microsoft' )
, ( 2, 'Microsoft 120', 'Microsoft' )
, ( 3, 'Microsoft 130', 'Microsoft' )
, ( 4, 'Nokia 72', 'Microsoft' )
, ( 7, 'iPhone', 'Apple' );
Select * from Mobiles
Select * from Mobiles_New
MERGE [dbo].[Mobiles] AS [OLD_Tbl]
USING [dbo].[Mobiles_New] AS [New_Tbl]
ON ( OLD_Tbl.[MobileID] = New_Tbl.[MobileID] )
WHEN MATCHED AND OLD_Tbl.[MobileName] <>
New_Tbl.[MobileName]
OR OLD_Tbl.[Company] <> New_Tbl.[Company] THEN
UPDATE SET OLD_Tbl.[MobileName] = New_Tbl.[MobileName]
,
OLD_Tbl.[Company] = New_Tbl.[Company]
WHEN NOT MATCHED THEN
INSERT ( [MobileID] ,
[MobileName] ,
[Company]
)
VALUES ( New_Tbl.[MobileID] ,
New_Tbl.[MobileName] ,
New_Tbl.[Company]
)
WHEN NOT MATCHED BY SOURCE THEN
DELETE
OUTPUT
$Action,
INSERTED.MobileID,
INSERTED.MobileName,
INSERTED.Company,
New_Tbl.MobileID;
Result:









{kind=link}